Research Projects
Projects done during the course of my PhD work at the University of Florida under Dr. My T. Thai. I studied approximate methods for discrete optimization with a focus on its applications in social networks analysis.

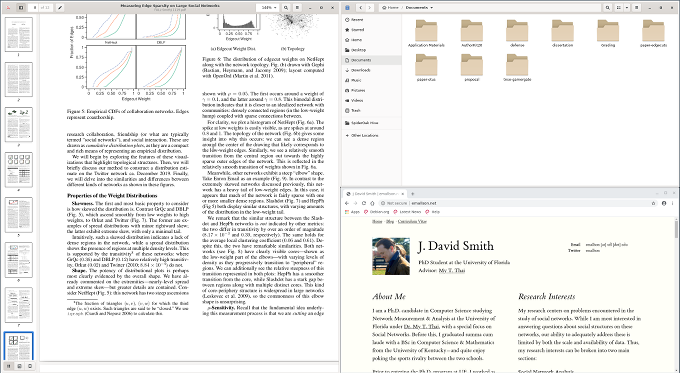
The shape of these gives insight into network structure. For example: the "elbow" shape of Enron Email indicates a dense core with sparse periphery.
Measuring Community Structure on Social Media
In the study of modern social networks, we work with networks under very restrictive access controls. My goal with this project was to develop a method to measure community structure in an unsupervised fashion that functions despite such limitations.
To accomplish this, I developed a novel method to calculate the local sparsity of a connection on the network, which is closely related to community structure. Using state-of-the-art Monte Carlo estimation methods, my approach is query-efficient enough to run on Twitter in a reasonable timeframe. Further, I developed a scalable, highly-parallel Rust implementation to calculate the distribution of this quantity on very large networks—and explored what this summarization can tell us about the network structure.
Efficient Optimization on the Integer Lattice
Most optimization problems can be divided into two pieces: the constraint system on which you solve, and the function that you optimize under those constraints. Many traditional problems use a simple size constraint paired with a function that has diminishing returns (or, formally, submodularity)—a property that leads to very powerful results for approximate optimization.
We developed an algorithm to optimize a much broader class of functions on a more powerful constraint system known as the integer lattice. I built an efficient Rust implementation of our method, which we used to show that our approach is faster than prior work both in a holistic sense and in terms of query requirements—without a drop in solution quality.

Three algorithms are shown: Fast- (our primary contribution), Threshold-, and Standard-Greedy.


Our algorithm is the first to be able to provide a guarantee greater than 63% for this problem. Due to our low sampling complexity, we are able to provide a 90% guarantee in less time than some prior work could provide a 63% guarantee.

The remaining algorithms decay down to their guarantees (a bit below 63%) as the problem size grows.
Optimizing Information Spread
One of the core functions of social networks is to spread information. It is natural, then, to ask how we can maximize such spread. Unfortunately, even evaluating the expected spread is very difficult—it is in class #P and requires exponential time to do exactly. Nonetheless, in this project we developed an efficient, approximately optimal algorithm to solve this problem.
We used a sampling-based approach to estimate the optimization surface efficiently. In fact, the number of samples required ended up being so low that we switched from the traditional greedy algorithm to an Integer Programming approach to improve our approximation guarantee to be at least 1 - ε times the optimal. I built the implementation we used from this: first in C++ with library code from previous projects, and subsequently a full rewrite in Rust along with safe wrappers for the C APIs of the CPLEX and Gurobi solvers to make the implementation obviously correct.

{kind=link}