Written by J. David Smith Published on 27 December 2023
This year, one of my hobby projects has been implementing some basic properties
and conversions between Matroids in
Lean.
My primary resource for doing this has been Theorem Proving in Lean
4 (TPiL),
which is an incredibly detailed walk through using Lean as a proof assistant.
While useful, it has...gaps—as does the main Lean documentation. A lot
of this gap appears to be filled by the Zulip
chat.
The title of this post is a bit of a double entendre: I am still a relative
beginner, writing what I intend as a companion to TPiL; and this is is intended
for beginners to Lean, covering that I wish I had known as a beginner myself.
A final caveat emptor: I haven't really hung out in Zulip and don't have a good
grasp on good code organization and style in Lean. These may not be best
practices, but they helped me.
This is organized in small sections covering individual things that I learned
the hard way while working on my hobby project.
Running Snippets
You can run the code snippets below in Lean or on the Lean website if you paste this prelude at the top:
example (S T : Finset α) : S ⊆ T -> T ⊆ S -> T = S := by
exact?
One of the biggest pain points early in my Lean experience was finding
theorems to use. The
mathlib
documentation is great, but lacking hoogle-style
search.
EDIT: Apparently not! LeahNeukirchen points out on
lobste.rs
two different hoogle-like search engines that I missed:
The rw?, simp?, apply? and exact? tactics give you specialized
hoogle-like access within the Lean environment, finding candidate theorems that
satisfy a specific goal and listing them in the editor UI. You can pick one of
the solutions via code actions if using the LSP.
By default, all target the current goal, but rw? and simp? can have at forms:
example (S T : Finset α) : S ⊆ T -> T ⊆ S -> T = S := by
intro S_subs T_subs
rw? at S_subs
Input Goal:a Assumption:a = b or a ↔ b Output Goal:b
rw is the most direct of the 3. It applies a theorem or assumption that looks
like a = b or a <-> b to a goal that looks like a, substituting it with
b.
rw, unlike apply and exact, can be applied to non-goals to transform
them. This is very useful to massage theorems from different sources into
alignment to prove your goal.
example (S T X : Finset α) : S = X -> X = T -> S = T := by
intro S_eq X_eq
rw [S_eq, <-X_eq]
exact takes an assumption, along with any needed parameters, and uses it to
resolve the current goal. It is simplistic, but effective.
example (S T : Finset α) : S ⊆ T -> T ⊆ S -> S = T := by
intro S_subs T_subs
/- Finset.Subset.antisymm looks like: S ⊆ T -> T ⊆ S -> S = T -/
/- the S_subs and T_subs parameters leave us with S = T, which matches the goal. -/
exact Finset.Subset.antisymm S_subs T_subs
apply transforms your goal into a different goal using an implication. If a
proof of a exists in the current scope, it is applied (in which case you
basically get exact). Otherwise, you get a new goal a.
example (S T : Finset α) : S ⊆ T ∧ T ⊆ S := by
/- Finset.Subset.antisymm_iff.mp looks like S = T -> S ⊆ T ∧ T ⊆ S -/
apply Finset.Subset.antisymm_iff.mp
/- new goal: S = T -/
Importantly (so importantly I'll bring it up again later): an a ↔ b or a = b assumption can be converted to a → b (with .mp) or b → a (with
.mpr).
TPiL mentions sub-goals at several points and does briefly discuss have, but
I feel this area was glossed over. Adding sub-goals toward your larger goal is
an extremely helpful method of making larger proofs tractable.
The first (and seemingly most common) way to introduce sub-goals is by way of
have, which generally has two purposes. First: you can introduce smaller
goals that are easier to prove—sometimes even possible for Lean to prove
automatically.
/- While lean cannot auto-solve the outer statement, it can trivially solve the both steps with `exact?` -/
example [DecidableEq α] (S : Finset α) (e1 e2 : α) : e2 ∈ S → insert e2 (insert e1 S) = (insert e1 S) := by
intro e2_mem
have : e2 ∈ (insert e1 S) := by exact?
exact?
Second: you can use it to instantiate other theorems for re-use:
/- (not runnable) -/
have T_card := ind_rank_eq_largest_ind_subset_card ind (insert e2 S) T T_subs T_ind T_max
In contrast, if / else is generally useful in cases where you need to
introduce a goal that relies on the law of the excluded
middle.
/- there is a theorem in Mathlib for this, but we use `have` to create smaller goals to bypass it -/
example [DecidableEq α] (S : Finset α) (e : α) : (insert e S).card ≤ S.card + 1 := by
if h : e ∈ S then
have : insert e S = S := Finset.insert_eq_self.mpr h
rw [this]
exact Nat.le_add_right (Finset.card S) 1
else
have : S.card + 1 = (insert e S).card := (Finset.card_insert_of_not_mem h).symm
rw [this]
Note that this, along with helpful theorems like not_not rely on classical
logic and as such are not strictly constructive (as far as my knowledge
indicates), but if/else in particular is such a useful means of organizing
my thoughts in the implementation of a proof that I opted to use it quite
heavily.
EDIT: It appears that Lean will only allow non-constructive uses of if /
else if you have used open Classical in the module. More
info
TLiP discusses handling cases with dots and cases _ with and match _ with,
but it wasn't clear to me how to handle the (labelled) sub-goals generated
other tools (like apply Iff.intro).
You can use case <label> => <proof> to handle a specific named proof.
This couples well with refine, which is like exact but generates sub-goals for (named or anonymous) placeholders:
example (S T : Finset α) : S ⊆ T -> T ⊆ S -> S = T := by
intros
refine Finset.Subset.antisymm ?left ?right
case left => assumption
case right => assumption
Beyond this, many operators expose helpful utilities. Using a > b as an example:
le produces b < a
not_le produces ¬ a <= b
asymm produces ¬ a < b
trans_le produces a <= c -> b < c
and many more. These are super handy for cases where (for example) you've got
your hands on a proof of a > b and need to prove ¬ a <= b, which happens
often with contraposition.
Input State: an assumption h, for which you can prove ¬ h from other assumptions Output State: the goal is replaced with ¬ h
This is useful in cases where you have constructed a contradiction in your
assumptions for a proof by contradiction, but the contradiction is not obvious
to Lean.
example (a b : ℕ) : a > b -> b > a -> True := by
intro left right
absurd right
exact left.asymm
Input State: a pair of assumptions h and h' which blatantly contradict Output State:No Goal
contradiction cuts out the extra steps of absurd in cases where the
contradiction is obvious to Lean. Typically, this means that you have
hypothesis h : a and h' : ¬ a.
example (a b : ℕ) : a > b -> ¬ a > b -> True := by
intros
contradiction
Input State: an assumption h Output State: the goal is replaced with ¬ h, and h is replaced with ¬ goal
Unlike absurd / contradiction, this is actually doing something
different: applying
contraposition. I'm including
it mostly because the tactic wasn't mentioned in TLiP and I often find that
contrapose is useful to simplify goals that involve negation in combination with rw [not_not].
/- a theorem for this exists in Mathlib, but again we're ignoring it -/
example (S : Finset α) : ¬ S.card = 0 -> S ≠ ∅ := by
intro neq_zero
contrapose neq_zero
rw [not_ne_iff] at neq_zero
rw [not_not, neq_zero]
rfl
The single thing that gave me the most trouble in my hobby project was the
proving of theorems involving existential quantifiers. It is important to
understand the constructive elements of Lean to fully understand the design of
existentials, and I think that TPiL does a pretty good job of explaining that.
However, that explanation doesn't really tell you how to prove existentials in
more complicated settings.
First off: existentials have the type Exist α β. This is a product type, much
like And, and can be destructured in a similar way:
have : ∃ x : N, x < 4 := sorryhave 〈x, x_lt〉 := this /- note that `x` is actually an N that exists satisfying x_lt! -/
This also means that your options for proving an existential are much like an
And. Principally: construct it with exact 〈x, h〉, x is some value that
satisfies h.
The question then: for complex types, how do you get an x? The answer: get it
from a method. bex seems like the common name for it. For example, to obtain
an element of a finite set S:
example (S : Finset α) : S ≠ ∅ -> ∃ x : α, x ∈ S := by
intro h
/- before getting an element from S, we have to construct the Nonempty type -/
have : S.Nonempty := Finset.nonempty_of_ne_empty h
exact this.bex
Once you're used to this, it starts becoming fairly natural. Retrieving
elements from collections generally requires proving that they are nonempty
(otherwise there may be no element to retrieve!), but that this was a totally
separate type (Finset.Nonempty in my case) was opaque and difficult for me to
discover.
Above, I discussed have as a means of introducing sub-goals to solve.
Alongside it exists a syntactically-similar tool: let. Specifically:
have <name> : <assumption> := <proof of assumption>
may be restated as:
have <name> : <type> := <construction>
which is then (almost!) equivalent to:
let <name> : <type> := <construction>
There is one key difference: let definitions are transparent, while have
definitions are opaque. In other words: if you want the rewriter to be able
to operate on the construction of a term, use let. Otherwise, have.
To see the difference, consider this example:
example [DecidableEq α] (a b : Finset α) (e : α) : ¬ e ∈ a -> insert e a = b -> b.card = a.card + 1 := by
intro mem h
let x := insert e a
have : x.card = a.card + 1 := by
rw [Finset.card_insert_of_not_mem mem]
rw [← this, ← h]
If let x is replaced by have x, then the inner sub-goal is no longer
provable—the definition of x has become opaque.
There is one other difference: which fields are optional. have requires
only the construction / proof field, while let requires at least the
name and construction fields (the type may be inferred).
My final note—and the only one on code organization—is to use small
theorems. If you example much of mathlib, you will find small proofs: a handful
of lines, at most. This is obviously helpful when you are familiar with the
library internals, but opaque as a reader on how exactly the proof is
constructed.
Don't let that discourage you from focusing on small proofs, though! There are
two strong reasons beyond vague "code architecture" considerations for this:
Small proofs can often be constructed automatically by Lean through
exact?, rw? or simp? (if not more advanced tools like
aesop), which means less work for
you.
The theorem lookup tactics start to perform noticeable worse with large
proof states, which makes the interactive experience worse.
This is not too much of a problem—my proof of submodularity of Matroid
rank functions derived from independence predicates is around 100 lines long
and remained at least usable—but certainly an element of UX that
coincides with good practice: small theorems, like small functions, are
generally easier to work with and this aligns with the practical performance of
Lean's interactive systems.
Overall, working through these proofs in Lean was a very instructive experience
for me. Being a relative beginner to proof assistants in general (having only
light experience toying with Emacs' Proof
General + Coq during
grad school), the quality of the LSP and other tools were huge boons. I wish
this had existed while I was working on theory stuff more actively, as it did
help me find issues with on-paper proofs that I'd done which held hidden
assumptions.
That said: it definitely was not a replacement for working on paper for me. The
degree to which Lean encourages small transformations caused me to miss the
forest for the trees in a very direct way. It is useful in verification of
theory, but not a replacement for sitting down with pen, paper, and tea and
working through a proof.
Hopefully these notes will be useful for others looking to use Lean as a proof
assistant (and, perhaps, people who are less committed to constructive theory
and are more than willing to embrace practical niceties like if/else and
not_not).
Written by J. David Smith Published on 19 August 2020
Recently, I wrote a bit about the
Gladiator League and how it came to be. Last week, the inaugural Jumpstart
(JMP) league ended, with the
Amonkhet Remastered (AKR) league taking
its place on Thursday. I wanted to take a moment to look back at the league, the
results, and the evolution of the bot during the almost-month of the first
league.
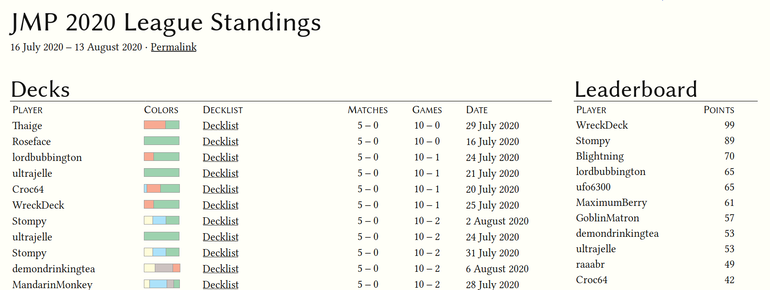
Let me begin by setting the stage. The JMP League ran from July 16th until late
on August 12th—a day shy of a full 4 weeks. During that time, 166 players
completed 416 league runs totalling 1,305 matches.
An average of
48 matches and 15 completed runs per day.
Not bad for the first run,
and—honestly—much higher than expected. The Gladiator community embraced the
Sharktocrab with open arms.
Unsurprisingly,
In natural systems, count data tends to be
exponentially distributed, with a few individuals having large counts and the
rest having very small counts.
Those of you more familiar with statistics will
note that the chart is flipped from a typical presentation of count
distribution that would make this more obvious.
the number of league completions each
player has is pretty heavily skewed. The typical player that completed at least one
run completed 2 runs, but 13 players completed at least 10 runs and two
players completed over 20!
Number of matches played during each hour of the day. This chart automatically
uses your computer's local time.
The times at which people play are fairly Amero-centric, but not to the level
that I was expecting. This is a bit surprising: the original Gladiator player
pool largely came from Wheeler's community, and he is on Pacific Time
(GMT-7/GMT-8). The peak hours are much more spread than one would
expect if there were only players in North America—which I'd guess is due to
a pretty sizable contingent of European players.
In the same vein, we can see a HUGE spike in matches played in the first 3
days of the League. That tapered off, remained fairly stable until the final
week of the League. I am curious if that last week of low play is due more to
AKR's impending release or tiredness of the League. To answer that, we'll need
to wait until we have a bit longer between set releases.
Breakdown of color representation in each week of the league. A deck is listed
as having a color if it has at least 5 cards of that color, and each deck can
contribute to multiple colors (so each box does not necessarily sum to 1). All
decks that completed all 5 matches are included. Decks are assigned to a week
based on registration date.
I tried doing all color pairings, but it was honestly illegible.
One of the hot topics during the league's run was, put simply, Green. Many
players (myself included) are of the opinion that Green cards were massively
pushed relative to other colors in recent standard sets. People
are—understandably—concerned that this may translate to a similar level of
relative strength in Gladiator.
Breakdown of color representation in each week of the league, filtered to only
include decks with at least 3 wins.
Before going further, I want to stress that League data is not a good source
for win rates. While it is appealing as one of the only sources of
structured match data on Gladiator, there are a couple of reasons to be very
careful when looking at League winrates. First: the League is very deliberatly
not competitive. Many players are not trying to play the best deck, only the
best version of their deck. This has major implications because power is
meta-dependent and the League is very unlikely to have a meta developed around
pure power in the same way that Standard may.
Second–and this is crucial—we do not have enough data to draw serious
conclusions for all but the most egregious outliers. 1,300 matches may sound
like a lot, but with a high-variance format in a high-variance game in a meta
that isn't centered on trying to win at all costs this data just isn't
sufficient to draw strong conclusions. I am not saying that we should abandon
hope, just that we should be careful.
This league is actually a great example of how metas evolve and change—and why
we shouldn't be too quick to draw conclusions. We can see
above that in the first two weeks of the League, decks with
Green scored 3+ wins at a much higher rate than any other color. Many of these
decks are built on Craterhoof
Behemoth, one of the
hottest cards from Jumpstart.
A great example of this is
Roseface's hoof list—the very first
5-0 of the league.
Hoof decks are explosive, and will run over anyone trying to durdle around
without interacting. Later in the league, we saw an uptick in the amount of
interaction played
Check out DemonDrinkingTea's Mardu
list for a good interaction-heavy
example from later in the league. Note that on top of the removal package, it
plays 4 board wipes (not counting Ugin).
—especially board wipes,
which are incredibly difficult for hoof decks to deal with.
While
SupremePhantom's (multiple)Bantlists all play Green, they also play
(most of) the on-color board wipes.
Interaction is valuable across the
board, and board wipes happen to be very good in a format built from several
years of creature-centric Standard sets. These factors combined with hoof no
longer being the hot new toy to bring Green back in line with other colors.
There is one deck in particular that I want to shout out, because I believe it
is a first for the format. UFO6300 5-0'd the league with a dedicated combo
deck. Historically,
No
pun intended.
we haven't had access to actually good combos in this
format. Pre-Ikoria, the only combos that I know of involved 3 card loops with
either Teshar or
Naru Meha that were
expensive, hard to assemble, and easy to disrupt.
UFO's list uses Emergent
Ultimatum
to assemble something just shy of
a 1-card combo. You find
Omniscience, Peer into the
Abyss, and Ob Nixilis,
Hate Twisted. If
the opponent chooses to shuffle Omniscience, you cast Ob Nixilis and then Peer
into the Abyss and dome your opponent for 40-50 with Ob's static ability. If the
opponent chooses to shuffle one of the other pieces, then you use Omniscience to
dig for it—if you have a tutor in hand you can guarantee that you'll find it
and win immediately.
They killed me on stream with this list. I
definitely picked the wrong option the first time.
This is the first combo I've seen do well
I don't count "ramp
into Omniscience and then durdle for 15 minutes" as a combo.
, and I'll
be interesting to see how it and other combo decks evolve in the format.
As much of the bot
JMP card-identifier issues notwithstanding.
had been built prior to the start of the JMP league, I was able to focus
on adding new features during the League. Below, I want to highlight a couple of
them.
You can check out the complete changeset for the JMP league
here.
The first addition I made was the introduction of a GraphQL
API. While I still have more
improvements to do to this on the technical end,
It still
dispatches far, far too many SQL queries for my liking.
it is
relatively complete—and I actually used it to obtain all of the data used in
this post!
One of the oft-understated maxims of computing is that names are hard. In that
vein, displaying cards in the deck viewer has been a fairly consistent pain
point. During the JMP League, I made rendering more consistent (it will now
always show the front face of a card). Additionally, I added a decklist export
button!
This seemingly-simple change actually had huge
ramifications, because you can only access the modern clipboard API when
connected over SSL. As a result, I had to update the League site to use SSL.
This feature still needs improvement, as it currently relies on the
oft-flaky TappedOut card tooltips to rename card entries.
One of my favorite things about the Penny Dreadful Standings
page is their gorgeous
color indicators for each deck, giving you an immediate look at what colors the
list contains. This league, I implemented a nigh-copy of it for the Gladiator
league.
When I say nigh-copy, I mean it. The implementation on the
front-end is very similar, and I shamelessly stole their colors, which happen to
work well with the existing site colors.
One thing that I'm not happy with from the current League is how the rollover
from JMP to AKR worked. Internally, I use UTC (GMT+0) dates for
everything—including League start and end dates. This meant that the JMP
League ended at 5pm on August 12th for players on the West Coast of North
America. Rather awkward, I think.
For the next League, this will be changed to be more inline with Arena's update
schedule. We haven't worked out the exact time-frame yet, but you can expect the
AKR league to end late the night before Zendikar Rising releases and for the
ZNR League to start shortly after Arena downtime.
On the whole, I'm very happy with how the JMP League went. I have more
improvements to the League bot planned for this month, and am looking forward to
seeing how the league and the format evolves over time.
If you have any questions, feel free to reach out to me on Discord. The code for
the charts contained in this post can be viewed
here.
Written by J. David Smith Published on 25 July 2020
A bit over one week ago—July 16th—we launched the inaugural Gladiator
league using my LeagueBot.
Despite some initial difficulties with JMP quirks,
Arena exports
multiple cards with the same set code and collector number. For example: and
Goblin Oriflamme and Rhox
Faithmender both get exported as 1 ..... (JMP) 130.
the launch was fairly smooth. In this short time we've had
251 league completions,
Only decks with the full 5 matches
played are counted here.
which has been very gratifying for me. You
see: while the LeagueBot may appear to have sprung into existence fully formed,
this couldn't be further from the truth.
I want to take this opportunity to walk through the history of the bot. Its
history is closely tied to my own involvement in singleton formats on Arena, and
so at the same time I'm going to cover some Gladiator pre-history.
The first Singleton event I can find record of on MTG Arena took place from
September 27th–October 1st, 2018.
Cards in Format:
1,006
The event offered a play queue for 60-card no-banlist singleton games.
Wizards would repeat this event later that year from December 3rd–7th and again
two months later from February 14th–18th, 2019. This is where my involvement begins.
I created a Discord server for Singleton shortly after Valentine's Day event ended and
posted about it on the MagicArena
subreddit.
At this point in time, I stuck with the 60-card format due to the small number
of cards in the format.
Cards in Format:
1,526
Given that
Petitioners and
Rats were the two most popular
(and most annoying) decks in each Singleton event, I might have also banned
them to try to encourage people to give it a chance—but I honestly don't
remember.
This discord never really took off, and while I will never know for sure why
that happened, I do know one reason. This is also the point at which I built the
precursor to the LeagueBot we all know and love: the Sharktocrab
Bot. I'd intended to build it out
into a LeagueBot inspired by Penny Dreadful,
but ended up being overrun with work shortly after and never quite got around to
it. At this point in time, I had initial plans for how to record matches in a
safe manner, but hadn't figured out some details like deck submission (would we
use the rising star AetherHub? the old guard Goldfish?). However, I also made a
fatal mistake with this bot.
Those of you that've used Discord for a while have probably seen the "React to
get speaking permissions" gatekeeping bots. That is one of the few features I
got implemented into Sharktocrab—and it worked! Except I would occasionally
get DMs about how it didn't—DMs that I could never reproduce. Later, I
realized the likely culprit was my use of Heroku's free hosting—which, though
free, comes with the caveat that your app may be put to
sleep if
there is no activity. While I can't know for sure, I believe that this is the
cause of those unreproducible bug reports.
Between my own lack of time and the obvious failure to start, the server rotted
away for the better part of the year. Then, on September 28th, 2019 corporat
created the Historic Canadian Highlander discord, and advertised it on
reddit
a short time later.
Cards in Format:
2,038
Petitioners and Rats were both on the initial points list, effectively
banning those decks for much the same reason that I had previously.
The first
tournament ran that weekend, a round-robin with 6 participants that was won by
Oogablast with a 4-1.
Tournament Results: 4-1
Oogablast
3-2
Roseface
3-2
Jesse
2-3
Corporat
2-3
Bertxav
1-4
Yuin
Within two weeks, a pool of regulars was already forming.
You'll
likely recognize some of them, like Roseface and GoblinMatron, from Gladiator
discord. Wheeler joined fairly early on, but wasn't an active participant in the
format til much later.
I joined about 3 weeks into the format, and won
a tournament for the first (and only) time playing Abzan Field of the
Mythics.
The deck wasn't actually very good, but it and tournament results around this
time highlight the problems with 100-card singleton with a small card pool: at
some point you just need good stuff to put in your deck. Midrange was clearly
very good, with a couple of aggro decks with good top-ends (Gruul, Boros,
Mono-Black) also putting up results.
Anyway, this core of players formed the bulk of tournament participation over
the next few months. Participation ebbed and flowed, but never really took off.
To corporat's credit, he was actively trying to generate & maintain interest in
the format with both weekly tournaments and periodic posts about said
tournaments on reddit. While the weekly tournaments certainly helped maintain
interest, there was a chronic lack of pick-up games during the week that, in my
opinion, were both a cause for and caused by the limited number of players.
All that changed on April 19th, 2020,
Cards in format
2,622
when Wheeler streamed Arena Highlander (then called Historic Highlander)
for the first time. The format exploded. The discord gained hundreds of users
basically overnight. At the same time, I had just graduated, COVID-19 had
frustrated my job search, and I suddenly found myself with copious free time.
With the sudden influx of players, I decided to finally finish what I'd started
more than a year prior and build the LeagueBot.
During that year, designs for the bot had been in the back of my mind with some
regularity. I had mapped out the flows for match reporting, and had ideas for
the registration process. Putting those designs into practice was mostly
straightforward, with Discord itself giving me the ultimate assist by making
uploads so seamless that I could use them for deck registration. One week later,
the week-long April 2020 Test
League went live—but not before
the format split.
I was not involved in many of the conversations preceding the split between
Arena Highlander and Gladiator, so I'll refrain from commenting on it. I
will say, though, that the timing was incredibly frustrating. I began work on
the bot on April 20th, and had made substantial progress on it by the time that
the split happened on the 22nd. While I'd hoped that the launch of the League
on the 26th would help drive continued interest in Arena Highlander, it became
apparent within about a month that the bulk of the new blood had followed
Wheeler to Gladiator.
To his credit: there was a clear effort to
accomodate the existing Arena Highlander format. For example, Gladiator
tournaments were deliberately not run at the same time as the existing weekly
Arena Highlander tournament, despite Saturday afternoon being an excellent
time for tournaments across time zones.
From the League FAQ: an attempt to encourage Gladiator players to participate in
the Arena Highlander League.
Around this time, I took a break. I found work, played other games, and let my
frustration with the failure of the league and with Magic in general
WAR–IKO was an awful time to be playing Magic.
subside. I
popped into the Gladiator discord in early June when there was discussion of
starting a league, but aside from that was largely uninvolved.
Then, on July 7th I (finally) reached out to Roseface about moving the
LeagueBot over to Gladiator. The only thing that really needed changing was a
few names that read "Arena Highlander" and the domain name it used. Two days
later, I heard back: 👍. The plan was to launch on July 16th to coincide with
the release of Jumpstart—giving just over a week to switch things over.
Cards in Format:
3,109
This was plenty of time, and I had the opportunity to add in a couple of new
features like the API. Aside
from the previously mentioned issues with Jumpstart card exports, launch went
smoothly. Seeing the Gladiator community jump into the league and play more
than I'd ever expected was…nice. I'll take it.
You might have noticed that throughout this I've tracked the number of cards in
the format. In just over a year, the number of cards on Arena has doubled. With remastered Pioneer sets, it may well double again by next year.
I think this is relevant to understanding the evolution of the greater
Arena-singleton format. For instance: prior to ELD, a 100-card singleton deck
would include anywhere from 3-5% of all cards on Arena,
60/2,038
is about 3%, 100/2,038 is about 5%. A typically Gladiator deck has around 60
non-lands, and 3c decks may legitimately play 90+ nonbasic cards.
which
means you would often dip into borderline (or even outright) draft chaff for
playables, especially in mono-colored decks. This means that your card quality
was relatively low compared to now (when one plays 2-3% of all cards), and led
to an abundance of 2-3c Goodstuff decks along with legitimate concerns that the
consistency of Petitioners / Rats decks could be problematic despite the
obviously low card quality. I'm glad those days are behind us, and am looking
forward to seeing how the increasing card pool lets the format further
diversify.
Written by J. David Smith Published on 12 February 2018
I rerolled from my Hunter (MM lyfe) to a Brewmaster shortly after the Nighthold released, and holy hell I didn't expect this ride. I was going to just play my already-110 BDK, but our other tank was a BDK and after the incident with Cenarius
A bug/weird interaction on Cenarius removed Marrowrend stacks much faster than they could be applied. This made tanking Cenarius pre-fix on a BDK really awkward and more difficult than necessary.
the raid team was kind of sketchy on having two of the same tank. So, I powerleveled my formerly-Windwalker Monk from 88 to 110 over a weekend and started tanking.
Since then, I've become active in the #brewlounge and #brewcraft channels in the Peak of Serenity Discord, tanked a bit of Mythic
5/9M T20. Less than I'd have liked.
, and picked up maintenance of the WoWAnalyzer modules for Brewmaster. All in the space of less than a year. Whew.
Now BfA has been announced and changes are rolling out on the alpha. Since Brewmasters have received no super noteworthy changes yet, it's the perfect time for a wishlist! Before we get to that, however, I'd like to break down what the Brewmaster kit looks like right now so we have some context for my BfA wishlist.
While meatballs
Guardian Druids
have held the title of "Dodge Tank" in the past, it now firmly belongs to Brewmasters. It is not uncommon to see people reach 70% or more dodge rates in practice thanks to our Mastery: Elusive Brawler. EB provides a stacking bonus to our dodge chance each time we either fail to dodge a dodgeable ability or cast certain spells.
The current list is Blackout Strike, Breath of Fire, and (with Blackout Combo and rarely used) Blackout Strike + Purifying Brew.
This mastery performs three functions: first, it boosts our overall dodge percentage; second, it allows use to consistently deal with dodgeable mechanics through proactive play (banking EB-generating abilities); third, it mitigates downsides of randomness-driven mitigation.
That last point is fundamental. Historically, dodge-based mitigation has been much inferior to reduction-based mitigation due to shear randomness: if you fail dodge several hits in a row, you can simply die.
Those more familiar with pre-MoP tanking may be confused by this. Dodge was a good stat! It is more useful to compare Dodge for brewmasters with Defense prior to its removal: defense capping prevented crushing blows from randomly spiking you. Reaching the defense cap was considered mandatory. Brewmasters (along with VDH) have by far the least armor of any tank (I have 2,940 armor without trinkets, while a similarly geared DK has 5k+ and a Paladin has 7k+), meaning that pre-Stagger melee hits are much larger.
Mastery prevents this from happening altogether. At current gear levels, many BrMs are guaranteed to dodge at least every 3rd hit without taking any actions. With the low cooldown of Blackout Strike, this gets close to a guaranteed every-other-hit dodge rate.
While Elusive Brawler significantly smooths our damage intake from melees, without further mitigation we would still be extremely spikey.
Smooth damage intake can be healed much more efficiently, lowering the strain on your healer's mana and reaction times.
Stagger, our second "mitigation" method not only addresses this, but in fact has led us to be the smoothest tank in terms of damage-intake despite our reliance on the inherently random nature of dodge. Stagger causes every hit to be partially absorbed (currently 75% with Ironskin Brew up and no specific talents or gear), with the absorbed damage spread over the next ten seconds.
The exact mechanics of it aren't quite straightforward. emptyrivers has an excellent overview of how it works on the Peak of Serenity.
Functionally, this means that every would-be spike of damage instead is translated into a much lower damage-taken-per-second effect.
Despite not reducing total damage taken, Stagger enabled ludicrous cheesing
Creative strategies that make otherwise-difficult mechanics nearly non-existant.
early in the expansion. A cap on the total staggered damage (at most 10x player HP) was patched in after Tier 19 ended. Though it doesn't affect normal gameplay, it does mean that previous cases of stagger cheesing were much riskier if not impractical.
On the whole, Elusive Brawler and Stagger together give Brewmasters a unique way of smoothing damage taken – turning what would otherwise be the spikiest tank into the smoothest. In particular, Elusive Brawler gives rise to gameplay that no other tank presently has.
If you haven't known the joy of tanking Tyrannical Blackrook Hold as a BrM: Smashspite's charge can be dodged. It still applies stacks, and will rapidly reach the point of one-shotting you through any and all cooldowns. This leads to an intense do-or-die minigame.
The second, active, half of Brewmasters' mitigation toolkit comes in the form of Ironskin Brew & Purifying Brew. Ironskin Brew increases the amount of damage absorbed by Stagger from 40% to 75%. Note again that this does not mitigate anything. Our active mitigation is instead packed into Purifying Brew, which removes 40% (without traits or talents) the damage that has been absorbed by Stagger but not yet dealt over time. These two abilities share 3 charges with a cooldown of 21 seconds each (reduced by haste). However, Ironskin Brew only lasts for 8 seconds, meaning that based on these charges alone we are not capable of maintaining the buff – let alone Purifying.
However, this cooldown is reduced significantly by correctly performing the conventional rotation since key rotational abilities (Tiger Palm and Keg Smash) reduce the cooldown of brews by a significant amount. This situation is further helped by the presence of the (mandatory) Black Ox Brew talent, which restores all 3 charges on use, on an effective 40-45 second cooldown.
BoB benefits from the cooldown reduction of TP and KS.
Combined, this gives each Brew charge an effective cooldown of around 6-7 seconds. Or, put another way: exactly enough to keep Ironskin Brew up 100% of the time and have occasional charges to spend on Purification.
This system sounds great. It leaves us with manageable DTPS over the course of a fight, while allowing us to mitigate large spikes such as Fel Claws with Purifying Brew. Unfortunately, it suffers from a fundamental flaw: prior to Tier 20, there was no cap on the duration of the Ironskin Brew buff. This led to effective BrMs ending fights with several minutes of time remaining on the buff, while still having plentiful brews to spend on-demand for Purification. In response to this, Blizzard implemented a cap of three times the buff duration (24 seconds with traits). This turned the previously-comfortable Brew system into one with an annoying buff to maintain and another button you rarely use. And when I say rarely, I mean rarely: pre-Mythic it is possible to go entire fights without needing to Purify due to low damage intake, and on Mythic bosses Purification may only occur a couple of times a minute. This leads to an unsatisfying situation where we have to jump through a bunch of hoops to hit 100% ISB uptime – which is nearly mandatory to avoid being DK- or DH-levels of spikey without the self-sustain, cooldowns, or utility to compensate – but then have excess charges that we worked to generate but can't use effectively.
On the whole, I like the Brew/CDR system. However, its flaws are noticeable and have no easy solutions. In conjunction with this system, Stagger has been on the razor's edge between hopelessly busted and borderline useless since its value fundamentally scales with the amount of incoming damage. On high damage fights, Purifying Brew provides excellent mitigation while Ironskin Brew keeps our damage intake smooth and easily healable. Below that point, Purifying Brew becomes worthless because we cannot reach a high enough level of staggered damage for purifying to be worth more than pressing Ironskin Brew again.
I won't spend long on this, but the current UI situation for Brewmasters is preeeeettty bad. The maintenance buff of Ironskin Brew is difficult to track on the default UI – a situation made worse by the fact that dropping it can lead to a quick, untimely demise. Worse: the Stagger bar caps out at 100% of your HP, which is quite frankly nothing. It is common for experienced brewmasters on #brew_questions to recommend not purifying at less than 100% of your HP staggered.
...Brewmasters are really good. They're a strong tank class for challenging content, fun to play, and have a distinct playstyle not shared with other classes. While flaws exist, the spec works despite them. There is still room for improvement, however, so now we get on to the part you're really reading this for: what I want in Battle for Azeroth.
The biggest complaint I have with the playstyle of BrM is the annoyance that is ISB. It is only interactive insofar as it requires not pressing Purify too much and executing your rotation well. Pressing the ISB button is merely an annoyance that is necessary to confirm you've done the other two things.
As we saw in Nighthold, we clearly can't leave it uncapped either. So, what do we do? An oft-suggested option is to make ISB baseline and reduce the CDR available for Purifying Brew. However, this seems unlikely to be effective either given how infrequently we have to Purify. It is clear from the Legion Beta posts that they intended for Ironskin Brew to be used as an active mitigation ability like Shield Block, but doing so left Brewmasters uncomfortably spikey in the interim.
My main issue with ISB as it stands is the needlessness of pressing that extra button during an already high-APM rotation.
I have logs with negative overall downtime since brews are off the GCD.
What if Ironskin Brew were just removed, an equivalent and appropriately-themed buff given to Tiger Palm / Keg Smash, and Purifying Brew's cooldown reduced to compensate? While clearly not a perfect solution (it doesn't solve the fundamental balance issues with Stagger, for example), it does eliminate my major annoyance with current Brewmastery.
You might notice that in the What We Have segment I never once mentioned utility. While we have some unique utility currently, it mostly boils down to (a) cheesing fights with Dodge & Stagger, and (b) Ring of Peace – both of which are highly situational. This is in stark contrast to Meatball's Savage Roar, Protadin's Healing & Bubbles, and Blood DKs. My wish for BfA here is just to have a bit to set us apart from other tanks.
On the BfA Alpha, we're getting a bit of "extra" utility in the form of Leg Sweep being made baseline. This is supported by AoE stuns being stripped from other classes, which means that the presence of Leg Sweep in our kit becomes more noticeable – especially if we are allowed to go into BfA with both Ring of Peace and Leg Sweep available together.
On the whole, Brewmasters don't have many talents that are just totally completely unusable garbage. Even Chi Wave, which is used in neither dungeons nor raid content, can be a decent talent out in the world. I've used every talent we have at some point for a reason beyond just trying it out – every talent, that is, except for the Level 45 Row.
The Level 45 row has exactly 1 talent in it: Black Ox Brew. Don't @ me. I will fight you. BoB is better, both empirically and in feelycraft, than either of the alternatives in every feasible situation. Going into BfA, I'd like to see that change. That may mean buffing the alternatives,
I'd love to have access to proper self-sustain through a buffed GotM
but more realistically it means that BoB just needs to get hit. The cooldown reduction it provides is simply too high – it is both immensively powerful at smoothing an entire fight due to its low cooldown, and excellent for dealing with specific mechanics like KJ's Fel Claws.
As I mentioned in the intro, I maintain the WoWAnalyzer modules for Brewmaster. This has been a lot of fun: the dev team is fantastic, #brewcraft has been super helpful in filling in the gaps in my knowledge, and the codebase is generally nice to work with. That said, it has not been without frustrations. Stagger in particular has been an immense nuisance. I rewrote what the previous maintainer (WOPR) had done so that I could add some extra features that were infeasible before, but that implementation sometimes breaks down for no apparent reason.
In BfA, I'd like to see the amount of staggered damage reported in the logs. There is already a classResources field that records things like energy, runes, mana, etc. While there may be technical limitations to adding Stagger to that list, I'd very much like to see it happen. It'd make my job significantly easier.
Playing Brewmaster during Legion has been one of the highlights of my WoW career, and I'm excited to see where we end up in BfA. Although I'm obviously hoping that not much changes since BrM is currently a lot of fun, I am hopeful that we can have some wrinkles ironed out in the transition to the next expansion.
Written by J. David Smith Published on 07 September 2017
It's one of those days where I am totally unmotivated to accomplish anything
(despite the fact that I technically already have – the first draft of my qual
survey is done!). So, here's a brief aside that's been in the back of my mind
for a few months now.
It is extremely common for the simulations in my line of work
Or our, hi fellow student!
to have a large set of
parameters. The way that this is handled varies from person to person, and at
this point I feel as though I've seen everything; I've seen simple getopt
usage, I've seen home-grown command-line parsers, I've seen
compile-time #defines used to switch models!
Fig 1: Me, reacting to #ifdef PARAM modelA #else modelB #endif
Worse, proper documentation on what the
parameters mean and what valid inputs are is as inconsistent as the
implementations themselves. Enough. There is a better way.
Docopt is a library that is available in basically any
language you care about
This includes
C,
C++,
Python,
Rust,
R, and even
Shell! Language is not an excuse for
skipping on this.
that parses a
documentation string for your command line interface and automatically
builds a parser from it. Take, for example, this CLI that I used for a
re-implementation of my work on Socialbots:
See
here for context on what the parameters
(aside from ζ, which has never actually been used) mean.
Simulation for <conference>.
Usage:
recon <graph> <inst> <k> (–etc | –hmnm | –zeta <zeta>) [options]
recon (-h | –help)
Options:
-h –help Show this screen.
–etc Expected triadic closure acceptance.
–etc-zeta <zeta> Expected triadic closure acceptance with ζ.
–zeta <zeta> HM + ζ acceptance.
–hmnm Non-Monotone HM acceptance.
–degree-incentive Enable degree incentive in acceptance function.
–wi Use the WI delta function.
–fof-scale <scale> Set B_fof(u) = <scale> B_f(u). [default: 0.5]
–log <log> Log to write output to.
This isn't a simple set of parameters, but it is far from the most complex I've
worked with. Just in this example, we have positional arguments (<graph> <inst> <k>)
followed by mutually-exclusive settings (–etc | –hmnm | ...)
followed by optional parameters ([options]). Here is how you'd parse this
with the Rust version of Docopt:
Although in this version type validation must be done manually (e.g. if you
expect a number but the user provides a string, you must check that the given
type can be cast to a string), this is still dramatically simpler than any
parsing code I've seen in the wild. Even better: your docstring is always up
to date with the parameters that you actually take.
Of course,
certain amounts of bitrot are always possible. For example, you could add a
parameter but never implement handling for it. However, you can't accidentally
add or rename a flag and then never add it to the docstring, which is far more
common in my experience.
So – for your sanity and mine –
please just use Docopt (or another CLI-parsing library) to read your
parameters. These libraries are easy to statically link into your code (to
avoid .dll/.so not found issues), and so your code remains easy to move
from machine to machine in compiled form. Please. You won't regret it.